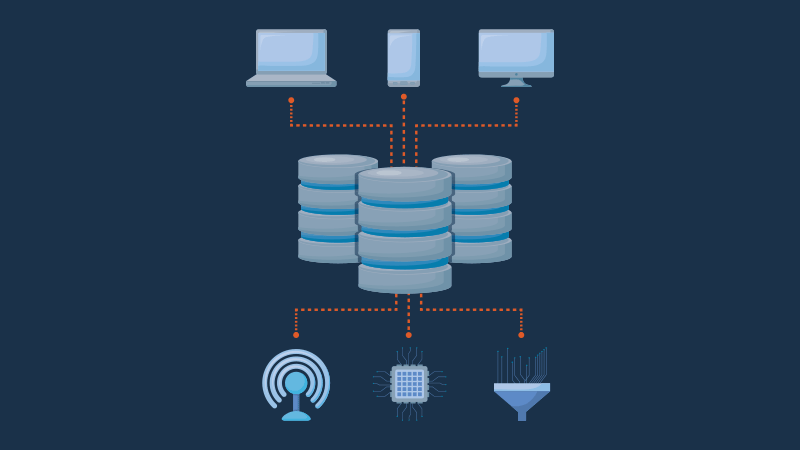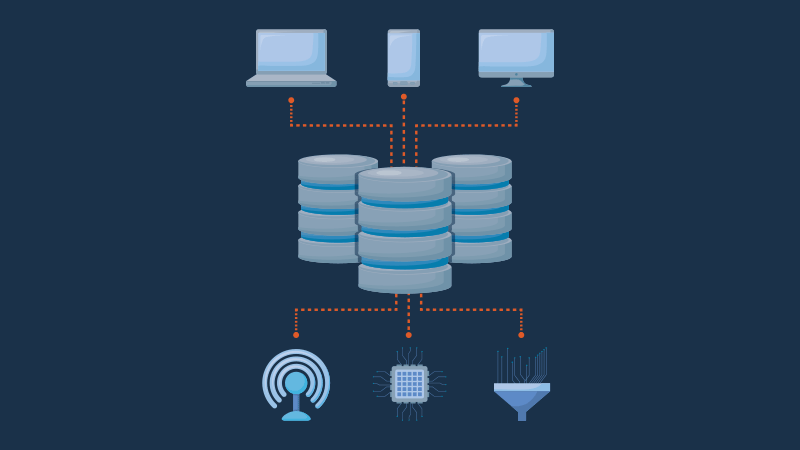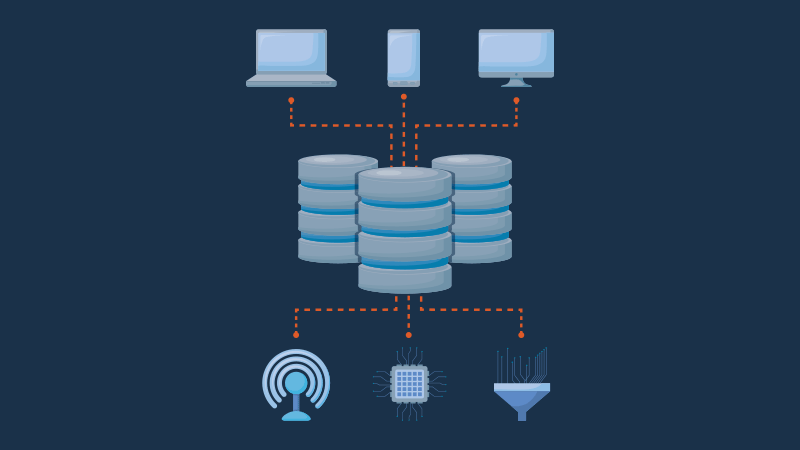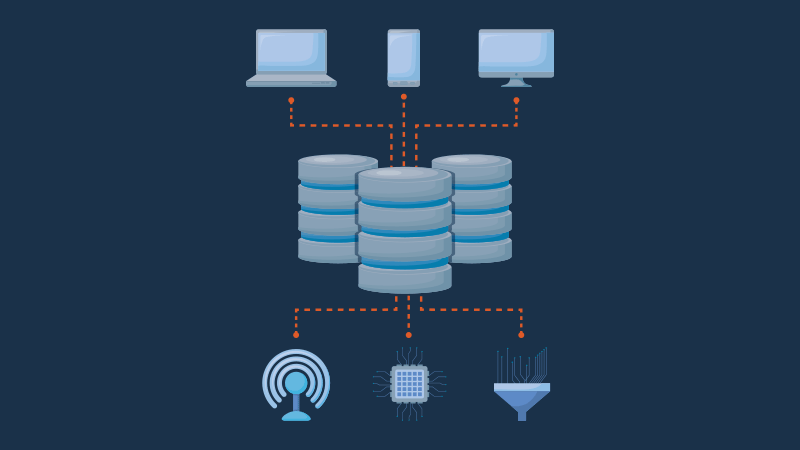
In today’s business environment, uninterrupted access to data is a baseline expectation. Systems must stay online, transactions must complete, and users must interact with real-time information without delays. These requirements apply whether a company operates globally or serves a single market. Reliability is no longer optional. It is assumed.
That expectation has placed a new kind of pressure on infrastructure. Centralized databases, once the standard for managing data, often struggle to meet the demands of modern systems. This is where distributed databases offer a new path forward. They are not built around a single server or node. A network of interconnected systems is involved. Each node works in coordination with the others to process requests, replicate data, and ensure continuity, even when disruptions occur.
This model changes the game. It does not just store data in multiple locations. It introduces resilience by design and enables availability across different failure conditions. Distributed databases are not just a technical upgrade. They are a strategic shift toward systems that adapt, recover, and perform under pressure.
The Principles Behind Distributed Databases
At the core of a distributed database is a simple idea: spread the workload across multiple systems to reduce dependency on any single point. Unlike a traditional database that lives on one server, a distributed database exists across many nodes, often located in different physical or geographic environments.
Each node plays a role in storing, processing, and serving data. These nodes communicate with each other to stay synchronized and ensure data consistency. When one node becomes unavailable, others step in to continue operations. This structure enhances availability, reduces risk, and enables performance that scales with demand.
There is also a redundancy benefit. Data is not stored in just one place. It is replicated across nodes. That replication acts as insurance. If one copy is lost or corrupted, others are ready to take over.
But the value of distributed databases goes beyond failover protection. They allow systems to distribute query loads, optimize routing paths, and serve users closer to where they are located. These features contribute to both speed and reliability, two pillars of modern system performance.
Availability as a Design Goal
Availability is not just about uptime. It is about delivering consistent access under a range of real-world conditions. Power failures, network outages, hardware issues, or software bugs can all impact system performance. A centralized database often has limited options when these problems occur.
Distributed databases handle these scenarios differently. They are designed with availability in mind from the start. If a node fails, traffic can be rerouted. If a server goes offline, a replica can take over. If a region is impacted, data can still be accessed through another location.
For organizations, this means fewer service interruptions, better user experiences, and more predictable operations. Customers do not notice when a node fails. Transactions continue. Data flows remain uninterrupted. Teams can respond without rushing into recovery mode.
Reliability Through Replication and Consensus
Reliability is often confused with availability, but the two are not the same. Availability means systems remain accessible. Reliability means they perform correctly. A system can be up and running but still deliver inconsistent or outdated data. That is not reliability. That is risk.
Distributed databases manage this challenge by using replication and consensus protocols. Data is written to multiple nodes, often at the same time. Before changes are committed, nodes must agree on the outcome. This prevents partial writes or conflicts that lead to errors.
This model ensures that data is not only present, but trustworthy. If a user retrieves a record, they can be confident it is accurate and current. If a system processes a transaction, the result is consistent across all nodes. Studies by the National Institute of Standards and Technology (NIST) show that distributed data replication enables retrieval even if 75% of replicas fail, demonstrating strong fault tolerance.
Scaling Without Sacrificing Consistency
Growth introduces complexity. As organizations add users, devices, regions, or platforms, the demand on backend systems increases. A centralized architecture may hit limits in storage, processing, or connectivity. That creates bottlenecks and impacts performance.
Distributed databases provide a more scalable foundation. New nodes can be added to handle increased load without disrupting the system. Data can be partitioned across different nodes to distribute pressure. Read and write operations can be balanced for optimal throughput.
The challenge in distributed systems has always been balancing scale with consistency. But modern distributed databases are designed to handle this tradeoff intelligently. Depending on the use case, they allow for configuration of consistency models based on what matters most to the application.
This flexibility gives developers and architects more control. Systems can be tuned to prioritize latency, accuracy, or fault tolerance depending on context. That makes distributed databases adaptable to real business needs, rather than forcing every use case into the same architectural mold.
Also Read: What Is Cloud Backup Posture Management (CBPM)? The Future of Cloud Data Resilience
Handling Failure Without Downtime
Failure in distributed systems is expected. Nodes may crash, links may break, or entire data centers may become unreachable. What matters is not whether these failures happen, but how the system responds when they do.
Distributed databases are built with failure scenarios in mind. When a node becomes unavailable, other nodes detect the issue and adjust automatically. Traffic is redirected, replicas take over, and recovery protocols begin in the background. Users rarely notice that anything has gone wrong.
This resilience is one of the primary advantages of distributed systems. They are not dependent on a single point of control. They assume things will go wrong and are prepared to keep going when they do. That mindset is baked into every layer of the architecture.
For organizations, this means fewer incidents, less disruption, and more confidence in the systems that support critical operations. Teams can plan maintenance or scale infrastructure without introducing unnecessary risk.
Supporting Modern Architectures and Use Cases
Distributed databases align closely with modern technology stacks. Microservices, edge computing, and cloud-native applications all benefit from decentralized data access. When different components of a system operate in different regions or environments, centralized data management creates lag and limits flexibility.
By contrast, distributed databases allow services to access data from the node closest to them. This reduces latency, improves performance, and simplifies integration. It also allows for greater control over how data is stored and processed, especially in hybrid or multi-cloud environments. For businesses building across platforms, this flexibility is essential. It enables them to deploy services globally while maintaining local responsiveness.
This architectural match between application design and data storage is part of what makes distributed databases such a powerful option. They are not just solving old problems in a new way. They are enabling entirely new kinds of systems that were not possible with centralized models.
Operational Efficiency Through Smart Management
Managing a distributed system requires a different approach. Monitoring, coordination, and optimization must happen continuously. However, modern distributed databases often come with built-in tools and management layers that reduce complexity.
Automation plays a key role. Administrators can monitor the system through dashboards and logs, make changes on the fly, and ensure performance through proactive alerts. This helps teams keep systems optimized without needing to manage every detail manually. It also makes distributed databases more accessible to organizations without large infrastructure teams.
FEMA’s Disaster Assistance Improvement Program integrated databases from 16 federal agencies using a service-oriented architecture (SOA), enabling seamless data sharing and reducing duplicate data entry for disaster survivors. This integration allowed real-time data transfer, improved coordination, and faster delivery of services to affected individuals
Long-term Strategic Value
Distributed databases allow companies to grow without being constrained by the limits of a single system. They provide safeguards against failure while supporting innovation. They align with cloud and edge environments, enabling teams to build systems that match the way the world works today.
They also support long-term resilience. Businesses can evolve their data strategy over time, introduce new services, enter new markets, or adjust their infrastructure model without rewriting the foundation of their systems.
Distributed databases are not a replacement for every workload. But where availability, reliability, and scale matter most, they deliver advantages that centralized models cannot match.
Conclusion
Distributed databases change how data systems are designed and operated. They don’t rely on a single source of truth. Instead, they distribute data across networks, increase availability through redundancy, and ensure reliability through coordinated consensus.
This architecture offers a firm foundation for organizations that require flexibility, uptime, and consistency. It supports modern applications, handles failures gracefully, and scales to future needs.
In an environment where access to data must be constant, and systems must perform regardless of location or load, distributed databases offer a model built for today’s demands and tomorrow’s possibilities.